DPS数据处理系统v16.05
完善的统计分析功能涵盖了几乎所有的统计分析内容,是目前国内统计分析功能最全软件包。但我们仍然期待着您的建议,不断地吸纳新的统计方法,使DPS系统的统计分析功能更加完善。
更新日志
DPSv11.50高级(试用)版推出
发布日期:2009-09-19很多科技工作者、高等院校学生以及统计软件爱好者,从网站下载DPS之后,由于试用版对样本容量和变量个数有限制,不能体验DPS的完整功能。为此我们推出可对经过标记处理数据,和正式版一样进行演算、统计分析 的试用版。因此我们的专著,即《DPS数据处理系统-实验设计、统计分析和数据挖掘》中所有例子 数据,可用现在的DPS试用版正常地进行统计分析了。
几年来,有许多学者撰写出版的统计专著,用DPS作为统计分析工具,我们计划在征得作者同意后,将专著中的例子数据予以处理,放在我们网站,供读者下载、并应用DPS试用版进行演算、分析。
结构方程模型(Structural Equation modeling)功能加入到DPS系统之中(2009年度DPS软件升级开发的重点工程)
发布日期:2009-07-21结构方程模型,无论从理论、到实施都比较复杂。让用户通过直观、简易地操作、轻松地创建结构方程模型,是我们开发结构方程模型功能的目标。在我们的DPS数据处理系统之中, 用户采用直观的拖放绘图工具,无需编程,以绘制路径图、所见即所得的方式,建立用户所需要的结构方程模型。模型里面提供了偏最小二乘求解、极大似然求解、和广义最小二乘求解等3种技术。
结构方程模型功能放在DPS的“多元分析”菜单下面,操作时,将观测变量数据,以一行一个样本,一列一个观测变量方式,在DPS的电子表格里编辑、并用鼠标选中,然后在菜单方式下进入结构模型建模用户界面。
附件是操作建模基本过程。
目前,结构方程模型的主要功能已经完成。但由于结构方程模型较为复杂,今年我们将继续完善,用户有何好的建议,请发邮件给我们,以便我们能做得更好。(电子邮件:qytang@zju.edu.cn)
《测树学》中的树干解析功能加入到DPS系统之中
发布日期:2009-04-05应用户要求,我们将树干解析功能加入到DPS数据处理系统之中。在编辑数据并选中之后,执行“专业统计”->“测树学数据分析”中的“树干解析I型”功能。
数据挖掘工具-支持向量机功能加入到DPS数据处理系统企业版之中
发布日期:2009-02-04详细内容请下载说明文档。
《DPS数据处理系统—实验设计、统计分析及数据挖掘》第二版初稿完成。
增广随机区组设计试验已增加到DPS系统企业版之中
发布日期:2009-01-05增广设计(augmented design)主要是为了克服当有多个对照时,对照小区占用试验处理较多而提出的。增广设计中,若干个对照或需要比较的处理(对照处理)仍采用标准设计,而“增广”的处理则安排选系。增广设计的主要特点是试验可以同时安排有重复的对照(品种)和无重复的增广处理(选系)。对照按一般设计在各个区组中进行重复试验,增广处理一般较多,但仅在试验的某一区组里面出现一次。
增广试验结果可以进行3种不同类型比较,即增广处理间、对照处理间和增广处理与对照处理间的比较。
增广设计适用于大量的无重复的处理筛选试验,因为增广处理数目任意,所以处理较灵活。增广设计有增广随机区组设计、增广拉丁方设计等,DPS目前提供的使用较多的增广随机区组设计。
增广随机区组设计,设试验有b个区组,v*个处理(v*=v+v1)。这里v为对照处理,即v个品种;另外有v1个增广处理,即v1个选系。增广随机区组设计是使v个对照品种在每一区组中均有一个小区,而选系v1仅在某一区组中各有(且仅有)一个小区。
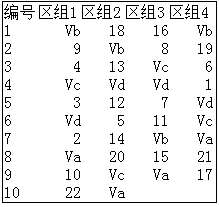
增广随机区组设计,需要对对照品种和选系进行随机化,试验方案的设计较为复杂。DPS中提供了增广随机区组设计生成方法。用户至于在第一行依次放入各个对照品种名称,第二行依次放入各个选系的名称,再执行增广随机区组设计即可。例如有4个区组(b=4),4个对照品种(Va, Vb, Vc, Vd),22个选系(编号为1~22)。进行增广随机区组设计, 首先将各个品种、选系名称编辑如图所示。
增广随机区组设计数据编辑格式
然后执行“试验设计”下“随机区组设计”中的“增广随机区组设计”,并在系统提示学输入区组数“4”,即可得到如下试验设计方案:
根据试验设计方案,可实施试验。
增广随机区组设计试验结果,因其中的增广处理效应和区组效应相互混杂,分析时一般采用不完全区组的区组内方差分析,对各个处理效应进行调整,一消除区组效应的混杂。这里以一个简单例子说明增广随机区组设计的统计分析过程。若有一个对照品种3个,选系8个,3个区组试验,先将原始数据整理成如图左上部所示。
增广随机区组数据及DPS处理格式
在DPS系统中,增广随机区组设计试验的数据分析,其数据格式须编辑成第5章中一般线性模型方差分析格式,亦即图中的阴影部分所示。这里共有3列,第一是处理(即对照品种、选系),第2列是区组,第3列是处理结果观察值。例如,图中左上部原始整理表中的第2个区组、品种b的观察值8.2,放在左边的第5行。
数据编辑完成之后,用鼠标选中待分析数据,在菜单方式下执行“专业统计·品种比较试验”下面的增广随机区组试验统计分析项。系统会立即给出所有的统计分析结果。
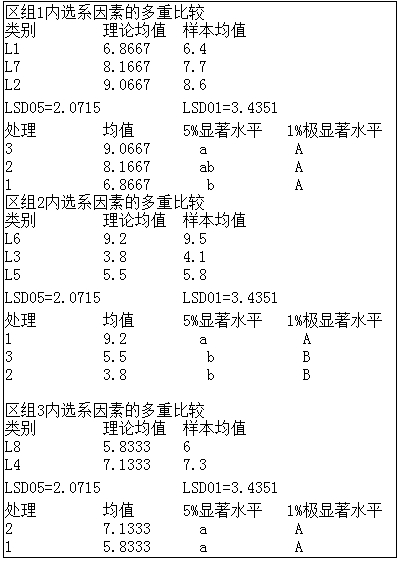
输出结果的第一部分是方差分析表,从方差分析结果可以看出,处理(调整)间F值等于8.8043, p=0.0252(p<0.05),差异显著;其中(对照)品种间F值等于5.4007, p=0.0730(p>0.05),说明对照品种间差异不显著;选系间F值等于9.6552, p=0.0219(p<0.05),表明选系间差异显著。
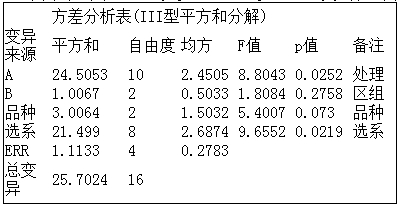
各个处理间多重比较,系统首先给出了对照品种间的比较结果。作为例子,尽管对照品种间F检验不显著,仍加以解释:在5%显著水平下,品种b和品种c的均数有差异。其它比较组别之间没有差异。
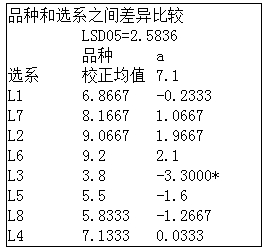
各区组内选系均数之间的比较,DPS输出了每个区组内选系的多重比较结果;并给出了区组内选系两两之间差异LSD测定的精确显著水平。本例中,区组I中,选系L1和L7间均数差异显著,其它选系间差异不显著;区组II中,选系L6和L5、L3间均数差异显著,但L3和L5间差异不显著;区组III中,选系L4和L8间均数差异不显著。
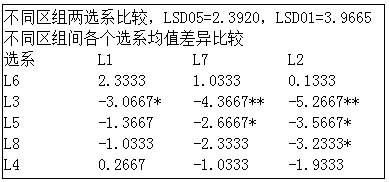
区组间各个选系均数间多重比较,以矩阵形式给出。比较表中的数值为差值,差值后面跟有一个“*”表示在5%显著水平上有差异,有两个“**”表示在1%显著水平上有差异,没有星号表示差异不显著
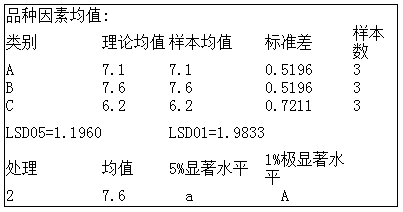
系统最后以矩阵形式输出了对照品种和选系间均数差异比较。比较表中给出了对照品种均数、选系的矫正均数,以及它们之间数值的差值。差值大于零表示选系均数高于对照品种的均数,反之亦然。差值后面跟有一个“*”表示在5%显著水平上有差异,有两个“**”表示在1%显著水平上有差异,没有星号表示差异不显著。