DPS数据处理系统v16.05
完善的统计分析功能涵盖了几乎所有的统计分析内容,是目前国内统计分析功能最全软件包。但我们仍然期待着您的建议,不断地吸纳新的统计方法,使DPS系统的统计分析功能更加完善。
更新日志
面板数据(Panel Data)分析建模功能已经加入到DPS系统之中
发布日期:2014-08-05面板数据分析用户界面。
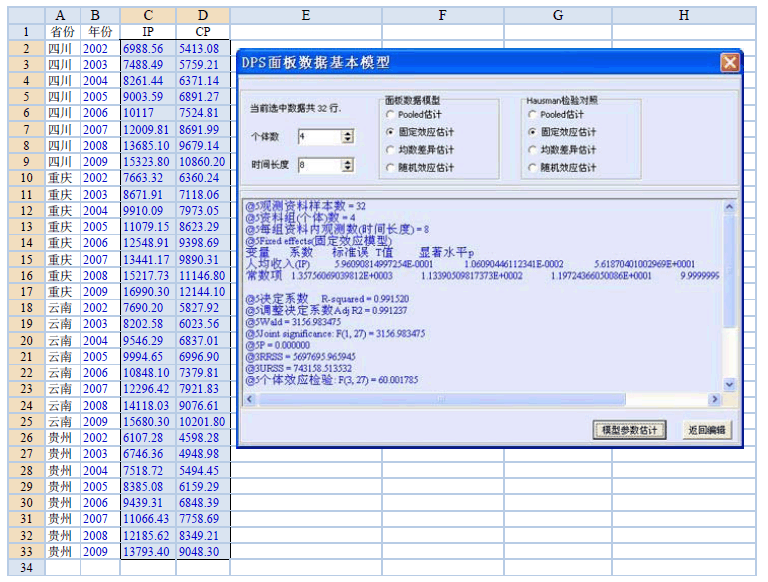
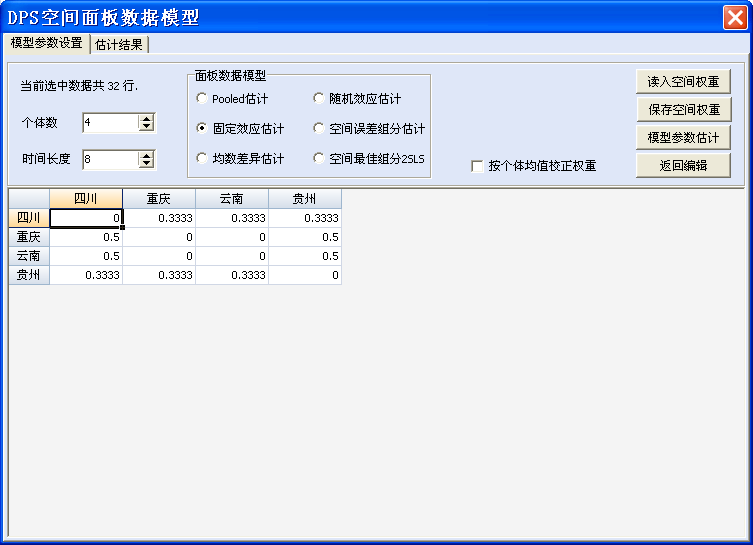
空间面板数据分析用户界面。
增加双重筛选逐步回归分析的模型整体检验及新的用户界面
发布日期:2014-05-22自张尧庭等(1980)提出双重筛选逐步回归分析算法以来,该技术在水文、气象等领域得到了较广泛应用。但双重筛选逐步回归统计建模过程中的统计检验都只是对各个因变量所建立的回归方程,多因变量模型的整体统计检验尚待研究。这是因为在双重筛选逐步回归分析中的多个因变量在取某一个筛选自变量的概率水平值时,某种自变量组合,对某一因变量而言可能达到了“最优”,但另外因变量而言可能还不是最优的,尤其在某一分组含有几个因变量时。
因此,从回归模型实际应用角度,需要给出一个对双重筛选逐步回归整体模型 “最优”性能检验的统计量。这个统计量应是反映双重筛选逐步回归的各个回归方程显著水平概率p值之“和”的统计量、并能检测双重筛选逐步回归模型整体显著水平。
我们这里,根据卡方值和概率水平p值关系提出了一个双重筛选逐步回归模型整体检验方法。因为当卡方分布自由度为2时,概率值p的自然对数,ln(p),等于dd。稍作换算,有:
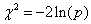
因此我们可根据该式将显著性概率值p取自然对数,转换成自由度为2的卡方值。由于几个卡方值的和仍是卡方分布,这样我们就可将每个回归方程的显著性概率p值,转换成自由度为2的卡方值进行相加,得到总的卡方值和自由度,进而对总的卡方值和自由度计算显著水平。对有m个因变量的双重筛选回归分析模型,模型整体最优的统计量,即整体显著性测验卡方值为 :
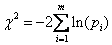 ,自由度df=2m
,自由度df=2m这样,我们应用卡方分布和概率值的关系、以及卡方值具有可加性的属性,就可得到描述这个多重筛选回归模型整体最优的统计量及其显著水平,并据此对回归模型进行寻优、优化。
根据双重筛选回归模型整体寻优的需要,DPS新增了双重筛选回归的用户界面:
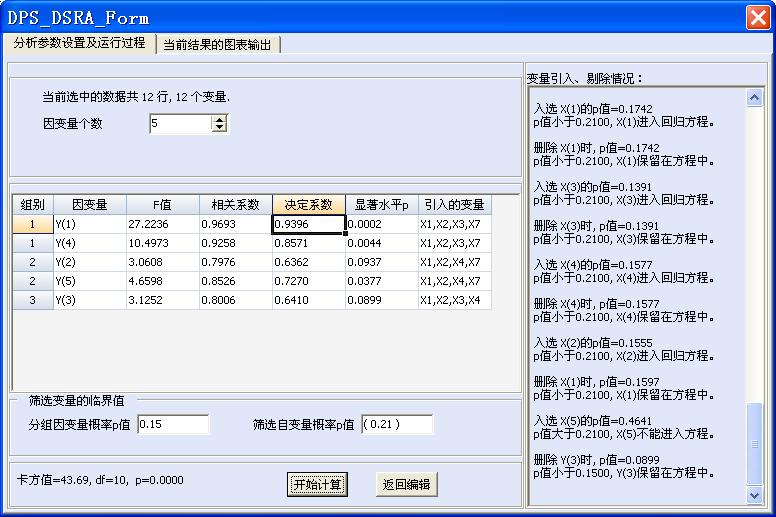
在用户界面中,首先在因变量个数右边输入框中输入因变量的个数;然后在有下部“筛选变量的临界值”下部框中输入因变量分组的概率临界值,以及筛选自变量概率p值,然后可进行分析。
如果筛选自变量的概率临界值的输入框空着,那么系统就会在0.05~0.50范围内,以前面介绍的模型整体检验统计量(卡方)为目标,寻找最优自变量临界值,完成双重筛选逐步回归分析。
对于教材中的例子数据:
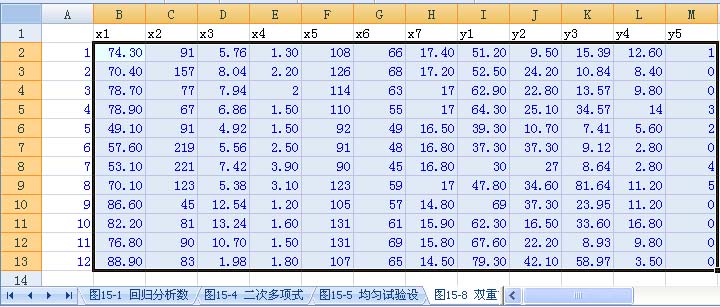
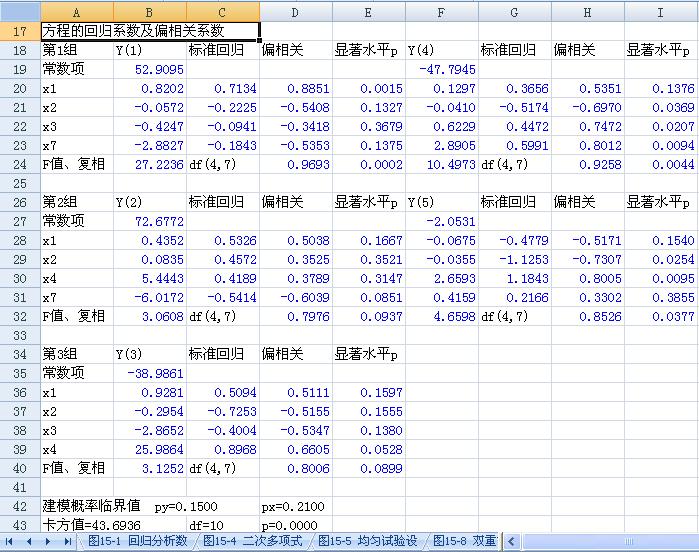
进行双重筛选逐步回归分析,用户界面如前面的介绍,执行计算后,返回编辑,得到如下结果:
混料实验设计中,具上下限约束的极端顶点设计中的D最优算法已达国际领先水平
发布日期:2014-04-22许多混料试验,不仅受到各成分之和等于1的约束,常有某些因素成分须被限定在某一范围内,即不是在[0,1]范围内任意取值,而是受到下限ai和上限bi约束,即0≤ai≤xi≤bi≤1(i=1,2,…,p)。当分量受到上、下界约束限制时,则因子空间将是标准单纯形空间内的一个不规则的凸多面体。一般来说它的形状很复杂,很难用一个简单的线性变换将其转化为单纯形。目前,极端顶点设计(亦称极角点设计)是解决兼受上、下限约束的混料实验设计问题的一种常用方法。
极端顶点设计,一般是采用Snee 和Marquardt (1974) 及Snee (1975) 开发的XVERT算法,先构建极角点设计。找到角点后,用单纯形中心法继续依指定顺序生成角点组合。
XVERT法,首先对上下限具较小范围p-1个因子的下限和上限,构建的2p-1个设计方案。然后,根据因子值必须总计为1的这一限制计算出省去的那个单因子的值。如果该点处于因子范围内,则将其保留。如果该点不在因子范围内,则它将进行增量或减量以使其处于该范围内,从而使这些点仍满足初始限制。
XVERT算法创建了实验可行区域的极端顶点,但极端顶点只是实验设计因子空间的一部分,须以极端顶点为基础,再由极端顶点平均得边界中点,三极顶平均得平面矩心,四极顶平均得四面体矩心,…,依此类推。直至所有极顶平均得P维矩心。
应注意的是,在按以上步骤确定极顶、中点、矩心的过程中,有可能产生相同的处理组合;这时应只保留一个。由于极端顶点设计是一般化的混合试验设计,可在一定程度上概括顶点设计和矩心设计。例如某闪光装置化学成分变化界限是如下:
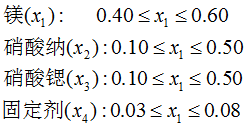
试验指标是亮度,试验目的是寻找闪光亮度最大时各个成分的混配比例。这里如按构造{4,2}极端顶点设计方法,先应写出以上界或下界为成分值进行搭配的极端顶点。但由于每一点的成分总和必须等于1,因此在四个成分中最多只能有三个取其上界或下界值进行搭配,留出一个空档,以便在其它三个值确定后再在空挡中添入合适数值,使成分总和等于1。具体做法是:
首先留出成分x4为空挡,写出x1,x2,x3以各自上、下界成分的一切可能搭配(表1中组合1~8号)。再填x4值使得各成分之和等于1。由于x4的取值范围是0.03≤x4≤0.08,无法选择适当数值,使各成分之和等于1,因此这里没有极端顶点。
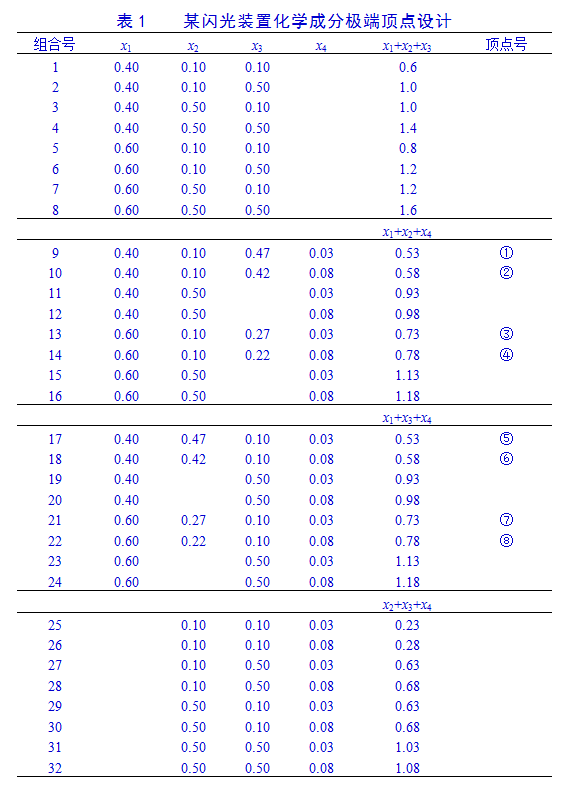
然后留出成分x3为空挡,写出x1,x2,x4上、下界成分的一切可能搭配,再填入x3值使各成分之和等于1,且0.10≤x3≤0.50。可得顶点①②③④(表1中组合9~16号)。
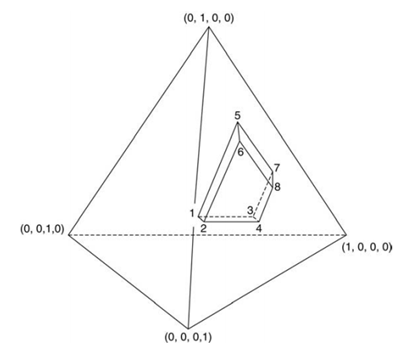
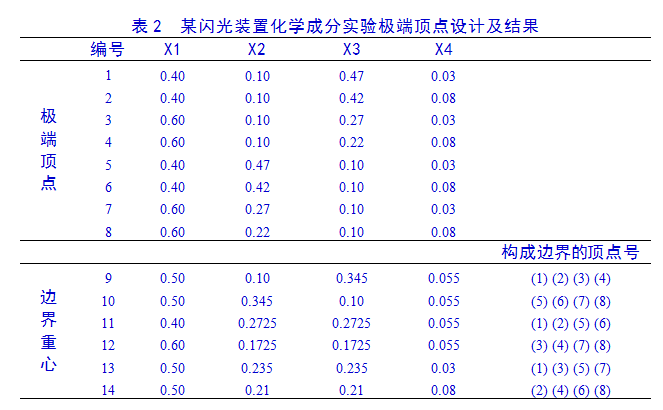
考虑到对实验数据建模分析,本问题中回归系数有C14+C23=10个,多于极端顶点个数。因此,要增加一些由极端顶点构成的面和体的中心作为试验点。显然,从图12-5中可以看出,由1,2,3,4四个极端顶点决定的面的重心就是这四个顶点(1,2,3,4号试验)坐标均值(0.50,0.10,0.345,0.055)。这样我们就可得到由8个极端顶点得到6个面(图1)。由8个顶点、6个边界面重心组成14个试验点(表2)
实际混料实验方案,实验顶点的设计完成后,对许多含因子成分较多的实验而言,会生成一个含实验点远超过实际实施规划的实验点集合。这时还只是建立了一个混料实验处理的候选试验点表格。进行实验还需根据实验要求,从中挑选出一个“好”的子集作为试验设计方案。
试验设计方案“好”的标准,一般是采用D-最优准则。D-最优准则是指实验设计矩阵的行列式值较大。例如,为寻找最优配方,一般需建立Scheffé二次型回归方程,如配方中有三种原料,比例分别为x1,x2和x3,指标y与x1,x2,x3之间的Scheffé二次型回归方程为
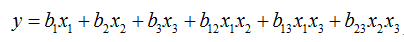
DPS从候选试点表格中挑选实施处理点的原则也是D-最优准则。但最优设计数值算法与目前著名的Fdeorov算法和Dn一最优确切设计数值算法中的Wynn一Mithcell单点交换法、或相应的改进算法不同。因为这类方法,随着实验成份、即维数增加,原有的方法因为运算量剧增而变得不是很有效。因此我们另辟蹊径、研究新的数值设计方法,并成功地应用到DPS系统的混料实验设计中。很好地解决了D-最优准则下实验子集选择的问题,形成了实用的软件工具。
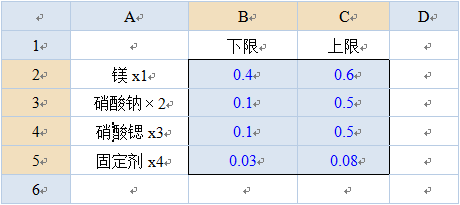
在DPS系统中进行极端顶点混料设计,其数据格式为:一行一个因子,一行中放该因子试验限制条件的下限和上限,并将下限、上限数据选中(图2)。
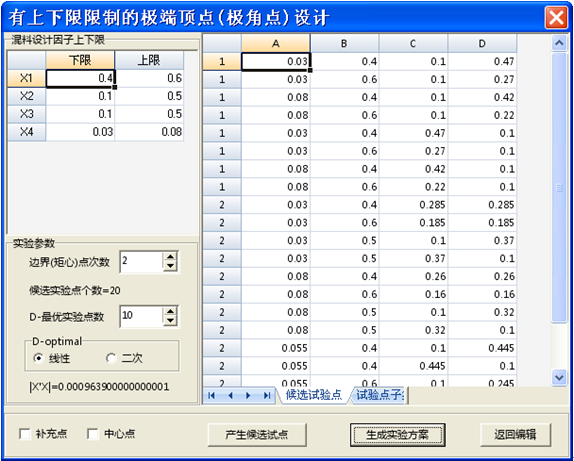
再在“实验设计”下的“混料试验设计”里面,执行“XVERT极端顶点设计”功能,这时系统弹出极端顶点设计用户界面(图3)。
图3的用户界面,左边是实验设计条件的设置;右边是实验设计结果,包括候选实验点集合、和实验设计点的子集的电子表格。
在图3的用户界面中,用户可以根据需要指定相关实验参数。“边界(矩心)点次数”取2时表示以极端顶点为基础,再由极端顶点平均得边界中点;取3时表示由三极顶平均得平面矩心;取4时表示由四极顶平均得四面体矩心,…。选中“补充点”表示在极端顶点和中心点之间的1/2处插入实验点。
D-Optimal 设置项里面的线性/二次项,控制系统挑选实验子集时,计算D-最优指标,即|X’X|中的X矩阵是否是设计矩阵的二次多项式。
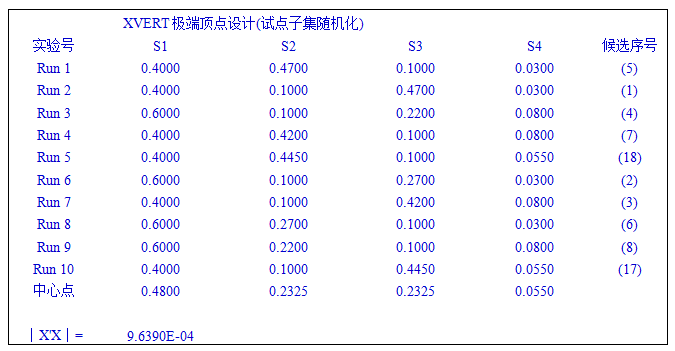
本例中,添加边缘(中心)点次数取2,D-Optimal设置为线性,实验次数取10,得到在D最优准则下的极端顶点设计实验设计矩阵如下:
以《JMP试验设计(第6版)》中含5个成份混料设计例子,各个成份的限制条件为:0.40≤x1≤0.60, 0.10≤x2≤0.30, 0.10≤x3≤0.30, 0.10≤x4≤0.40和0.03≤x5≤0.08。应用DPS极端顶点设计,和JMP极角点设计相比,试验点较少时,得到的结果和JMP相同。
该例有5个组分,如建立Scheffé二次型回归方程,在D-Optimal准则下挑选试验因子子集,应以设计矩阵的二次多项式的行列式值作为D-优良性指标。在试验设计专用软件Design-Expert中有D-最优设计的Scheffé二次型优化设计选项,因此我们这里和Design-Expert专业试验设计软件的设计结果进行比较。
比较时,Design-Expert软件分别采用两种算法,即Coordinate exchange法和Point exchange进行D-最优子集查找。Coordinate exchange steps(6-100)参数设置为50,D-optimal max exchanges(0-10)参数设置为10 。实验点子集的实验次数分别设置为20、25和30时,实验子集二次型D-优良指标,即二次型试验矩阵的行列式值结果见表4。
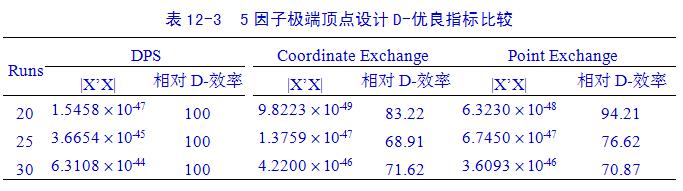
应用行列式值,计算D-效率测度(D-efficiency measure)F值,F值计算公式为:
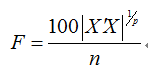
再根据F值, 以DPS的为100,得到专业试验设计软件Design-Expert应用Coordinate Exchange算法,当试验次数分别是20、25和30,相对D-效率分别为83.22、68.91和71.62;而应用Point Exchange算法时相对D-效率分别为94.21、76.62和70.87(表4)。
从表中可以看出,应用DPS在Scheffé二次型条件下,以D最优设计为原则,查找出的实验点子集,其设计矩阵行列式值均较Design-Expert软件设计出来的要大,D-最优指标更好,即|X’X|更大,这表明DPS发展出来的D最优算法的设计效果更好一些(表4)。
经过多年的探索,我们在混料设计的D最优算法方面、终于达到了国际领先水平!
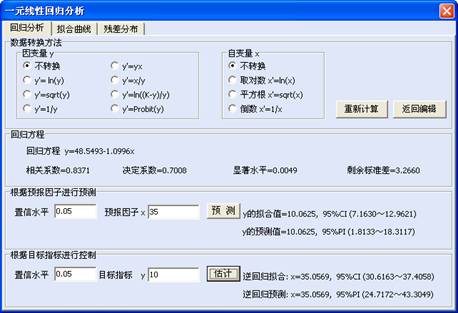
新增一元线性回归用户界面,使得用户处理数据更方便
发布日期:2014-04-5新增的一元线性回归用户界面共用3个页面:第1个页面是显示回归分析主要结果及供用户进行交互操作的界面;第2个页面是回归拟合曲线及其置信区间图;第3个页面是各类型误差显示、识别界面。在新的用户界面支持下,曲线回归分析中的数据直线化方法,可以可直接在一元线性回归的用户界面上部提供数据转换方法来实现。
新增重复观测(试验)数据回归分析功能
发布日期:2014-03-28重复试验数据格式,若自变量x共k次处理,第i次处理有ni个重复试验结果y。如果每次处理的重复观测次数ni都等于m,那么这样得到的因变量y的ni个重复观测的回归数据格式如下:
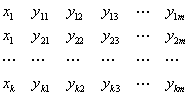
重复试验数据回归分析。其建立直线回归方程,和一般线性回归分析一样,只要把重复试验数据看成是无重复试验数据,即按k×m个数据点用通常的方法(即最小二乘法)即可建立直线回归方程。但在统计检验时,对y的总离均差平方和(SST)及其自由度(dfT)分解成3个组分,即R(回归)、L(失拟-偏离线性的偏差)和试验误差E。
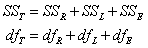
式中各平方和SS计算公式如下∶
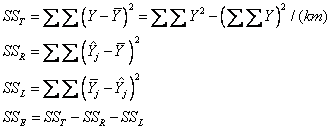
自由度分别为:dfT=km-1, dfR=1, dfL=k-2, dfE=k(m-1)。
各离差平方和含义,SSR(回归平方和)是由于x的变化而产生的,SSR越大,说明回归的贡献也越大;SSL(失拟平方和)是由于用来表示该数据偏离线性回归模型程度,SSL越大,意味着数据偏离线性回归模型程度越大、统计检验推翻此模型可能性也越大;SSE(误差平方和)反映因变量观测值y的试验误差,SSE越大,意味着试验精度不高,这也可能是被观测指标y的和x的关系是曲线性质的。
拟合效果的F检验,首先将离差平方和(SS)除以相应自由度(df),得到均方(MS)。
首先对失拟,即数据的各重复偏离线性程度进行F检验:无效假设H0∶MSL=MSE, 备择假设H1∶MSL≠MSE。检验统计量F1=MSL/MSE=[SSL/(k-2)]/[SSE/(k(m-1))]。F1服从df1=k-2、df2=k(m-1)的F分布。根据计算得到的F1值,及其相应自由度,计算出显著性水平概率p值。
若p<0.05,则可拒绝H0,说明SSL中除含有试验误差影响外,尚含有其他因素影响。这时需查明原因,再作研究。其影响可能有∶除x外,至少还有其他不可忽视因素;或y与x是曲线关系;或y与x无关。此时,即使用F2=MSR/MSE进行的第2次F检验的结果显著,仅说明求得的直线回归方程有一定的作用,但不能说明此方程是拟合得很好的,仍需查明原因,改变数学模型,作进一步研究。
若p>0.05,则可接受H0,表明SSL基本上是由试验误差等偶然因素引起的,此时,可将SSL与SSE合并起来对回归方程作显著性检验。其假设与方法如下:
H0∶所求得的直线回归方程不显著,H1∶所求得的直线回归方程显著。F检验值F2为,F2=MSR/MS(L+E)=(SSR/1)/[(SSL+SSE)/(km-2)]。F2服从df1=1、df2=km-2的F分布。根据计算得到的F2值及其相应自由度,亦可计算出显著性水平概率p值。
若p<0.05,结论是拒绝H0,可认为回归方程是显著的,这时的“显著”表明该回归方程可用。否则,就说明x的一次项对y没有多大作用,原因可能是由于试验误差过大; 也可能是由于并不存在对y有显著影响的因素。
例如 用血压计重复对不同年龄人群的血压进行测定,得收缩压测定数据如图所示:其中xi为测定对象年龄,yij为收缩压,每个对象测定3~5次。试分析测定误差。
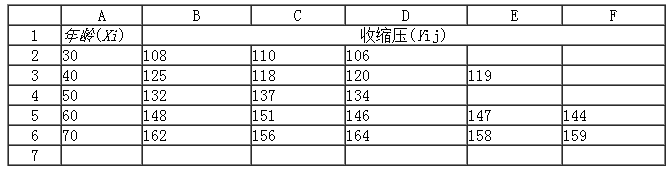
输入数据时,先输x值,再输y数据阵,如果各x对应的y的例数不等时,依次输入y值即可。然后在DPS的“试验统计”—“相关和回归”下面的“重复性试验回归分析”,系统出现用户界面。
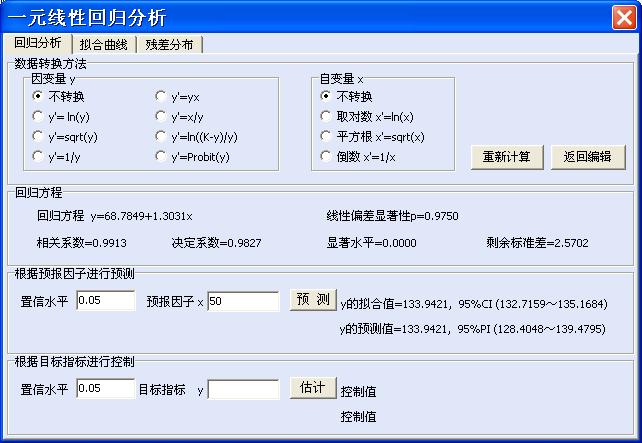
用户可能认为重复观察实验数据线性回归分析用户界面和一元线性回归用户界面相同。是的,的确相似。但图这里在回归方程后面多了一项线性偏差显著性水平p值,这正是重复观察数据回归分析和一般线性回归分析的差别所在。这里的线性偏差(Deviations from linearity)检验p=0.9750,说明SSL(线性偏差,亦即失拟部分)基本上是由测量误差等偶然因素引起的。重复观测数据回归分析得到的数值结果如下。
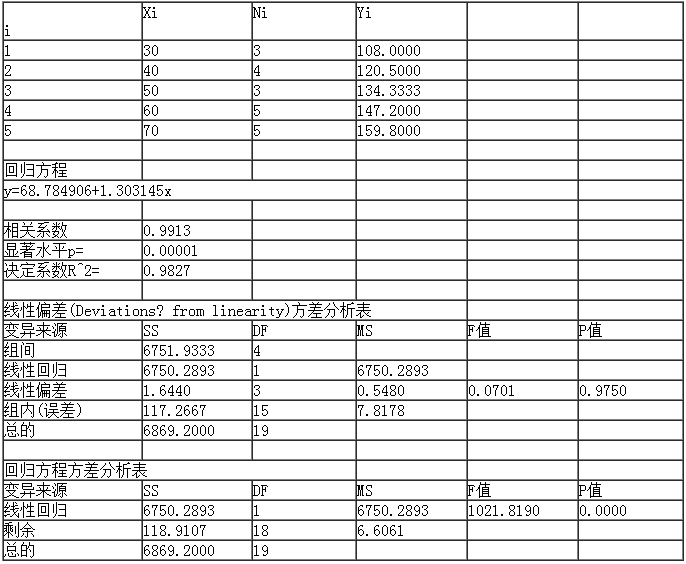
输出结果中,首先是按一般线性回归建立的回归方程,y=68.784906+1.303145x,相关系数等于0.9913,p<0.0001,决定系数R2=0.9827。
因线性偏差检验F=0.0701,p=0.9750,说明SSL(线性偏差,亦即失拟部分)基本上是由测量误差等偶然因素引起的。这时可将失拟部分合并到误差里面去,再检验回归方程是否有显著性,得到第2个方差分析表。其实,前面的相关系数检验p值实际上已给出将失拟部分合并到误差中后的回归方程检验结果。
逐步回归分析用户界面改进
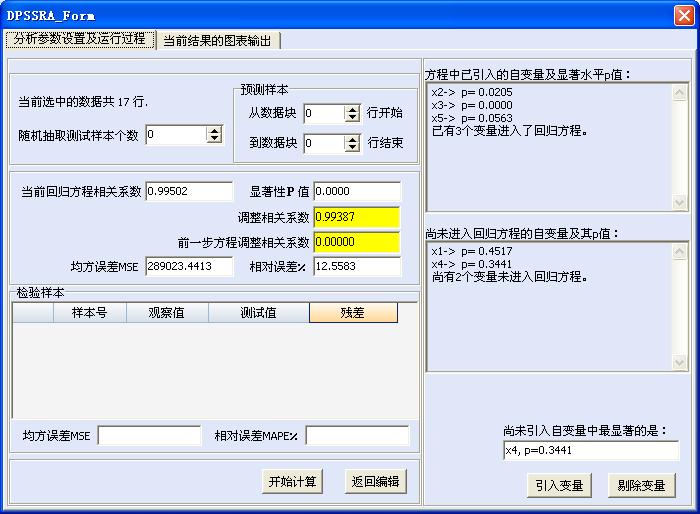
发布日期:2014-03-15为适应科学研究的需求,逐步回归分析用户界面,可将用户分析处理的数据分成训练样本、测试样本和预测样本3个部分。其中预测样本由用户指定它在数据块里面的起止行号。测试样本指定数量后,在分析时系统自动、随机地从分析样本中抽取。
在逐步回归分析时,系统首先默认所有的数据都是训练数据:即没有预留检测验证样本和待预测的样本,如果待预测样本的y值空着,视为数值0。并在a=0.1的置信水平下挑选自变量,并自动调整F值以保证选入至少一个自变量因子,出现如图所示用户界面。