DPS数据处理系统v16.05
完善的统计分析功能涵盖了几乎所有的统计分析内容,是目前国内统计分析功能最全软件包。但我们仍然期待着您的建议,不断地吸纳新的统计方法,使DPS系统的统计分析功能更加完善。
更新日志
水文气象频率分析
发布日期:2016-09-10极端天气气候事件不断发生, 已越来越引起各个学科领域及社会公众的关注。为了研究极端气候产生规律、对未来进行预测, 首先须对各种极端气候要素(即极值)的分布进行统计模拟, 以便在未来平均气候预测背景下推断极值的各种统计特征, 这是预测、预报极端气候事件的基础。
水文频率分析(hydrologic frequency analysis),即根据某水文现象的统计特性,利用现有水文资料,分析水文变量设计值与出现频率(或重现期)之间的定量关系,揭示极端事件发生的频率及其程度。水文频率分析主要包括:利用现有水文资料组成样本系列,选择合适的频率曲线线型和估计它的统计参数,根据所绘制的频率曲线推求相应于各种频率(或重现期)的水文设计值。但近年来,主要用于水文气象频率分析的极值分析技术,已逐步应用到社会科学、经济科学、环境科学、保险精算学等诸多领域。
在DPS系统中,我们提供了十多种频率分布分析方法。频率拟合分析,一般可从参数较少的频率分布开始拟合,拟合结果选参数较少的频率分布种类。实际工作中,两参数的频率分布(正态分布、指数分布、Gamma分布及Gumbel分布),仅含位置、尺度两个参数,不含形状参数,分布形状由其分布的概率特征控制。因此我们将这4种分布汇集到一个工作菜单里面,供用户调用。3参数频率分布是频率分析的主要工具,因这里分布除含有位置、尺度两参数外,还含有形状参数,每个参数意义明确,因此应用较多。
如果3参数分布模型拟合效果欠佳,做可用DPS提供的4参数Kappa分布、或5参数Wakeby分布来拟合。这些含有较多参数的统计分布拟合效果比前面的3参数统计分布要好一些。不过以往人们在设计参数时估计算法时忽视了Wakeby这类分布的参数值空间不是连续的这一特征,仍采用传统参数估计技术,因此很多情形下获得的参数其实并不是“最优解”。
我们在研究Wakeby分布参数取值空间特征基础上,采用随机优化策略,在非连续参数取值空间,寻优优化。提出基于随机优化的“二次优化”算法,使得拟合过程更稳健、精度更高。
两参数分布频率分析
DPS系统中,我们提供了含两个参数的正态分布、指数分布、Gamma分布和Gumbel分布等4个频率分析方法,并提供了L-矩估计、间隔最大积估计和最小二乘估计等3种模型参数拟合方法,以适应常见的符合这些统计分布的数据资料频率分析。拟合结果,如果拟合残差相对误差小于5%,柯尔莫哥洛夫统计量的显著性概率p值大于0.05,则可认为所选分布模型和样本经验分布拟合较好。无须再选择其他统计分布进行拟合了。
两参数分布简述
1.正态分布(Norm distribution)
正态分布是大家非常熟悉统计分布,其概率密度函数的数学表达式为:
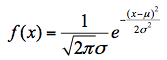
公式中包含了数学世界两个最重要的常量,π和e;两个待求参数,和σ,分别为位置参数和尺度参数。其累积分布函数为:
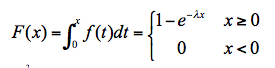
这里:
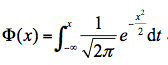
但正态分布分位数的计算没有解析表达式。因此正态分布频率分析其重现期计算需采用正态分布分位数计算。
2.指数分布(Exponential distribution)
指数分布亦是大家熟悉的、常见的统计分布,其概率密度函数的数学表达式为:
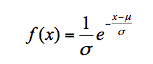
公式中包含了两个待求参数,和σ,为指数分布变量x的下界,≤x<∞,σ为尺度参数。其累积分布函数为:
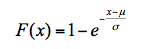
指数分布频率分析重现期计算公式:
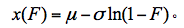
3.Gamma分布
Gamma分布,和指数分布类似,是处理偏态数据的统计分布,其概率密度函数的数学表达式为:
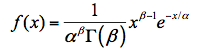
公式中包含了两个待求参数,和σ,为指数分布变量x的下界,≤x<∞,σ为尺度参数。其累积分布函数为:
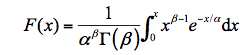
指数分布频率分析重现期计算,和正态分布一样,没有简单的解析表达式。因此重现期计算复杂一些。
4.耿贝尔分布(Gumbel distribution)
耿贝尔分布亦是处理偏态数据的统计分布。根据该分布的理论频率曲线来计算“多年一遇”的海洋水文气象要素的常用方法,目前耿贝尔分布亦被广泛运用于最大风速的计算当中。耿贝尔分布的概率密度函数的数学表达式为:
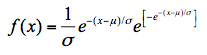
公式中包含了两个待求参数,和σ,为指数分布变量x的下界,≤x<∞,σ为尺度参数。其累积分布函数为:
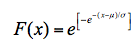
耿贝尔分布频率分析重现期计算公式,
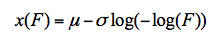
两参数分布DPS拟合示例
广义极值分布DPS的数据处理,数据格式如图42-1所示。图42-1是某河流60年来历年最大流量。编辑、输入数据后用鼠标选中数据即可进行两参数广义极值分布拟合。
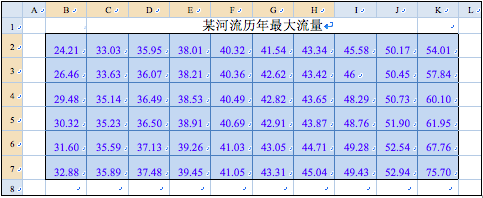
图42-1 水文频率分析数据格式
分析时,在菜单方式下调用选择数据后,在菜单方式下调用“专业统计”“水文气象频率分析”中的“两参数分布频率分析”,这时系统弹出如图42-2所示用户界面。
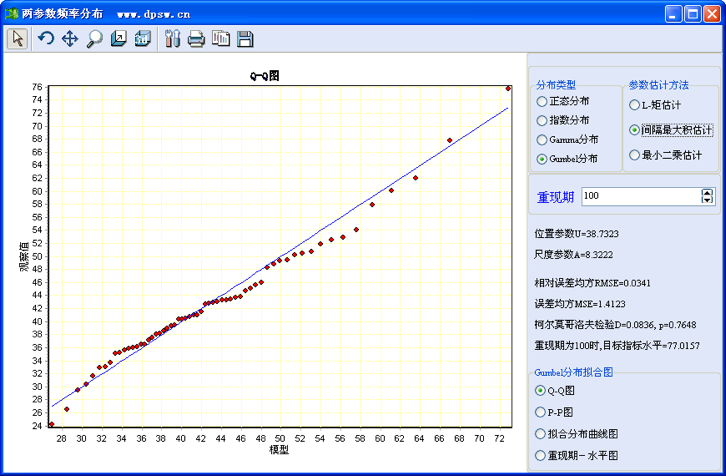
图42-2 两参数分布频率分析用户界面
图42-2用户界面显示了相关信息。用户界面右上角列出了4个两参数统计分布,及3种不同的参数估计方法。
选用哪个统计分布、及何种估计方法,应根据右边中部的数值结果初步判断:首先根据柯尔莫哥洛夫统计检验看拟合模型是否可以应用,即理论上需要柯尔莫哥洛夫统计检验的p值大于0.05,即理论分布和样本实际分布没有显著差异,这时该分布方可认为是成立的。然后根据相对残差均方、残差均方越小越好原则,看拟合精度是否较高,最好是相对残差均方值小于0.05,即5%。
用户界面右边下部,是频率分布图示的菜单,这里的图形,主要是第一个Q-Q图,该图显示了样本观察值(点)围绕统计分布理论直线的分布情形、图示样本点和理论曲线吻合趋势,可用于拟合效果是否可以接受的判断。
上面的数值结果和图示结果,在判断统计分布拟合效果方面、在大多数情形下是一致的,用户亦不难作出判断。
本例中,应用间隔最大积估计,4个两参数统计分布拟合结果中,Gumbel分布拟合结果柯尔莫哥洛夫统计检验KS=0.083554,p=0.7648,远大于0.05,模型可以接受。同时,相对误差均方RMSE为3.41%,误差均方MSE=1.4123,较几个其他分布都要小。因此Gumbel分布拟合结果在这里是最优的,可以用于重现期的估计。
Gumbel分布拟合结果的Q-Q图如图42-3。从图42-3的观察点偏离理论直线的情况可以看出,采用最大间隔积法拟合Gumbel分布的效果,无论是观察点解决理论直线的程度、或者观察点在图示中的分布趋势,都要好一些。因为这些观察点都围绕理论直线两侧分布,没有明显的偏离趋势。这也说明Gumbel分布拟合结果最好。

图42-3 各种两参数分布拟合结果Q-Q图
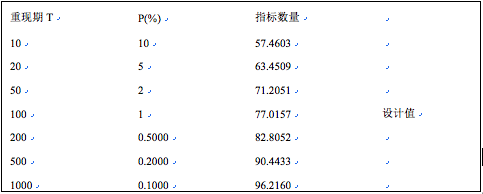
点击用户界面右上角,退出用户界面,返回电子工作表的编辑状态,可得到数值结果。Gumbel分布的间隔最大积估计,统计分布位置参数(U)=38.7323,尺度参数(A)=8.3222。并输出不同重现期的指标设计如下:
广义极值分布
极值分布,不注重研究变量x的分布,而是研究从很多个彼此独立的x值中(如不同年份日流量)挑出来的各个极大值,如由不同年份极大值形成的样本。这样的样本所服从的概率密度分布函数f(x)称之为极值分布。
极值分布,常用的是前面章节介绍的两参数Gumbel分布,即极值Ⅰ型分布。但由于研究对象的千差万别,仅采用极值I型进行拟合、计算重现期,在某些情形下可能是不恰当的。因此,为了使得极值分布更有广适性,更能满足实际工程设计的需要,目前一般应用广义极值分布来处理这类问题。
广义极值分布,它除了包含前面章节介绍的Gumbel分布(Ⅰ型分布)之外, 尚包含了Ⅱ型(Frechet分布)和Ⅲ型(Weibull分布)。由于广义极值分布包含了在统计性质上是连贯的三种型式的极值分布,即Gumbel分布、Frechet分布和Weibull分布,因此形成了一个较为完整的极值分布体系,能够避免单独采用某一分布的不足。
广义极值分布概述
极值分布是指观测值中极大值或极小值的概率分布。设X1,X2,…,Xn是服从广义极值分布的独立随机变量,这时其分布函数为:
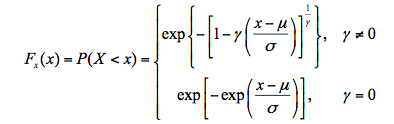
当 0时,广义极值分布趋于极值I型,即Gumbe1分布;当 < 0时为极值Ⅱ型, 即Frechet分布;当 > 0时为极值Ⅲ型,即Weibull分布。
广义极值分布DPS拟合
广义极值分布DPS的数据处理,仍以图42-1所示数据为例进行广义极值分布拟合。分析时,在菜单方式下调用选择数据后,在菜单方式下调用“专业统计”“水文气象频率分析”中的“广义极值分布”分析,,这时系统弹出如图42-7所示用户界面。
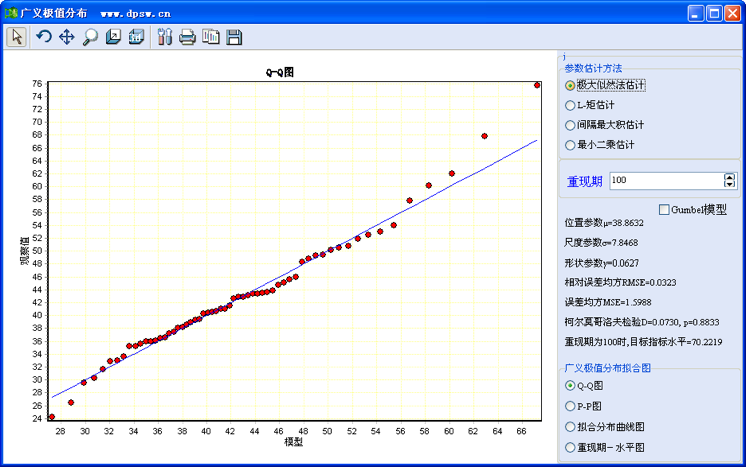
图42-7 广义极值分布拟合Q-Q图及其用户界面
图42-7用户界面显示了相关信息,以确定确定参数的估计、模型的选择:一般情形下,我们可以采用“最大似然估计”方法来拟合、估计模型参数,因为最大似然估计有许多优良的统计性质。如果用“间隔最大积估计”或“L-矩估计”进行估计,得到柯尔莫哥洛夫统计检验p值增大、相对均方误差、误差均方下降,以及图示样本点和理论曲线吻合度(吻合趋势)上升,那就可以考虑采用后面两种方法来进行参数的估计。
理论上,如果广义极值模型中参数接近于零,模型需采用Gumbel(极值I型)分布。怎样才算接近于零?用户在参数较小(如小于0.2)时,勾选一下界面上的“Gumbel模型”,拟合在=0的Gumbel模型,如这时得到的似然比概率大于0.05时,则从统计学角度来说,应该采用Gumbel模型;否则可认为极值模型中的参数,不宜将该参数去掉。即不宜采用Gumbel极值模型,而是应该采用带有参数的广义极值模型。
本例中,应用极大似然估计方法拟合广义极值分布,得到参数为0.0627,较小。这时可以尝试拟合Gumbel分布,勾选Gumbel分布模型后,系统给出如图42-6所示用户界面。注意这里的似然比卡方检验结果:似然比卡方为0.6329,p=0.4263。显然p值大于0.05,应该采用Gumbel模型拟合数据。
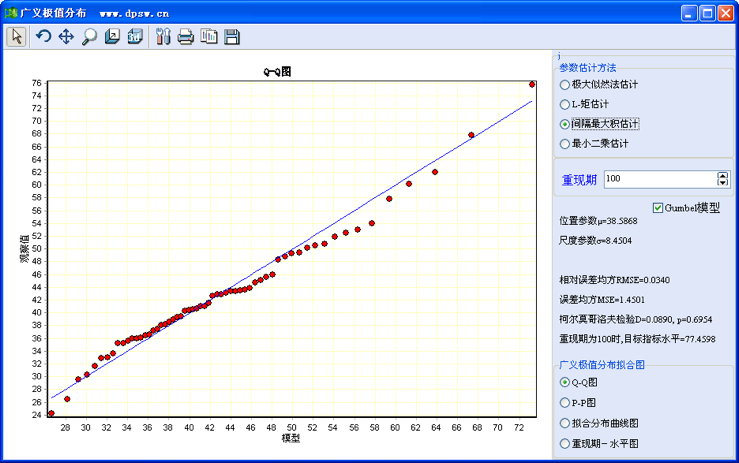
图42-8 Gumbel分布拟合界面
图42-8和图42-7相比,相对均方误差、误差均方下降,从数值检验来看,Gumbel分布拟合更为合适一些。进一步比较Gumbel分布参数拟合方法,当采用间隔最大积估计时,42-8中的Q-Q图观察值和理论值呈现在一条直线上,从这里可以判断,采用2参数的Gumbel模型,用间隔最大积估计得到的理论模型更为合适一些。
广义极值模型的一个主要应用是重现期的计算。在诊断模型,确认模型可以应用之后,我们可以修改重现期对话框后面的数值(缺省是100,即百年一遇),修改后DPS会自动给出相应重现期状态下的指标水平值。点击右下角的“重现期-水平图”,可以直观了解当前模型下不同重现期和指标阈值的关系(图42-9)
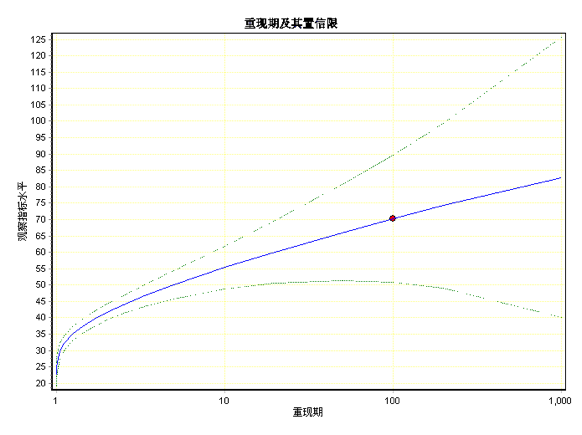
图42-9 不同重现期时的观察值指标水平趋势图
点击用户界面右上角,退出用户界面,系统返回数值结果如下:
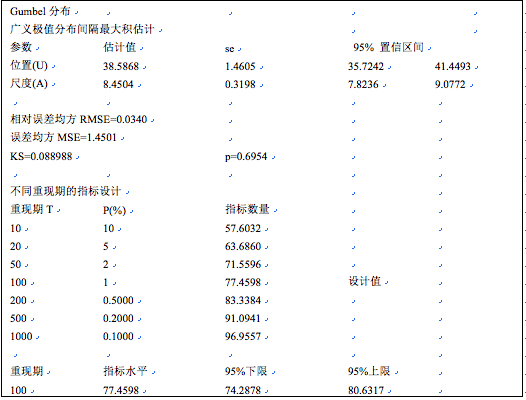
从数值结果我们可以看出,广义极值(I型)分布参数最大似然估计,位置参数为38.59,尺度参数为8.45。柯尔莫哥洛夫统计检验的显著性概率p为0.8899 (p>>0.05),模型拟合较好。重现期100时的指标是77.46,其95%的置信区间上限为80.63。
广义帕雷托(Pareto)分布
近年来,广义帕雷托分布(Generalized Pareto Distribution,GPD)已得到普遍应用。但目前国内在有关学科领域应用不多。自从1975年Pickands将这一分布模型引入到水文气象学研究中,其后Hosking等进一步发展了该模型的应用。GPD的最大优点在于它直接由原始资料数据(如历年)以给定门限值(threshold)为标准来抽取(每年)超过该门限值的极大(或极小)值,即用所谓“超门限峰值POT”(Peaks Over Threshold)方法抽样,其所需资料年限就可大大节省,从而增加了极值的样本量,克服了广义极值分布采用的单元极值(Block Maxima,BM) 或年极值(Annual Maxim a,AM)抽样方法的缺陷。
以往对洪水、暴雨等的极值分析主要是用经典的Gumbel分布,或改用广义极值分布。但这种方法的极大值抽样仅可用每年一值即年极大值AM方法。事实上, 同一年份中出现极大值的随机性变率相当大, 每一年抽取一个最大值并不符合实际。如有的年份可能多次出现超过警戒水位,而一些年份可能一次也没有。这种仅以每年取一个最大值的抽样方法, 势必会遗弃相当多的有用信息。按广义帕雷托(GPD)分布的定义,它可分析超过某特定临界值(即门限值) 的全部观测值资料集(如超过临界水位的洪水、大于某临界值的日(时)、候、旬或月的降水量、温度或大于某临界值的阵风风速等要素)。
广义帕雷托分布是韦克比(Wakeby)分布的特例。其逆函数为:

其分布函数为:
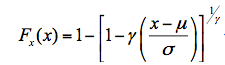
广义帕雷托分布DPS拟合
广义帕雷托分布DPS的数据处理,数据格式如图42-10所示。图42-10是某河流30年来历年最大流量。编辑、输入数据后用鼠标选中数据即可进行广义帕雷托分布拟合。
图42-10 广义帕雷托分布拟合用户界面
分析时,在菜单方式下调用“专业统计”“水文气象频率分析”中的“广义帕雷托分布拟合”,这时系统弹出如图42-11所示用户界面。
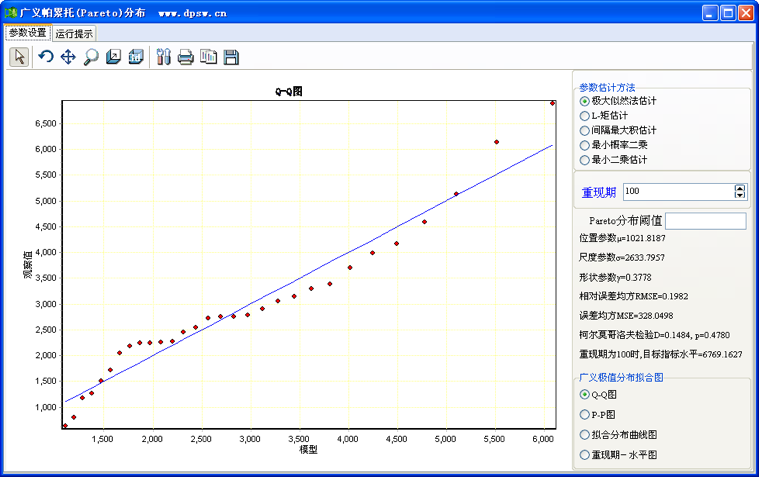
图42-11 广义帕雷托分布拟合Q-Q图及其用户界面
在广义帕雷托分布用户界面中,我们设置了一个Pareto分布阈值输入框。这里用户可以预先给定门限值μ之后,然后再进行拟合。门限值μ是根据一定条件给出的临界值。该值一般可事先定出各种标准临界值来做试验,也可按其“标准差”给出一倍,两倍或三倍“标准差”作为各种试验的临界值。但注意临界值不能小于样本中的最小值、或大于样本中的最大值。如果临界值栏空着,或输入的临界值出界,系统在极大似然估计时,自动将L-矩估计结果中的参数μ作为极大似然估计的临界值参数。
和广义极值分析用户界面类似,广义帕雷托分布分析用户界面亦显示了估计模型统计结果的拟合程度指标,如柯尔莫哥洛夫统计检验p值、相对均方误差、误差均方,以及图示样本点和理论曲线吻合度(吻合趋势)。
拟合模型是否可以应用, 理论上需要柯尔莫哥洛夫统计检验p值大于0.05。即理论分布和样本实际分布没有显著差异。当然,相对均方误差、误差均方越小越好,图示样本点和理论曲线吻合趋势尽量满意。
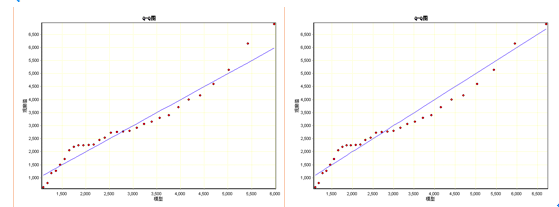
图42-12 不同估计方法拟合结果Q-Q图
图42-12中的左边是L-矩估计结果的Q-Q图,右边是间隔最大积估计结果的Q-Q图。结合图42-11中的最大似然估计结果的Q-Q图,比较这3种估计方法的拟合结果,显然,采用间隔最大估计方法的结果更为合适一些。
广义帕雷托分布模型的一个主要应用是重现期的计算。在诊断模型,确认模型可以应用之后,我们可以修改重现期对话框后面的数值(缺省是100,即百年一遇),修改后DPS会自动给出相应重现期状态下的指标水平值。点击右下角的“重现期-水平图”,可以直观了解当前模型下不同重现期和指标阈值的关系(图42-13)。
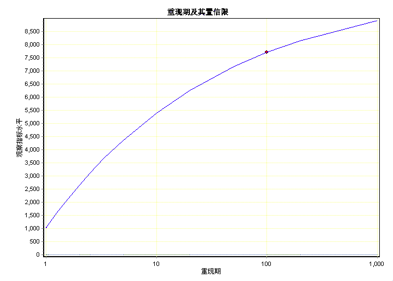
图42-13 不同重现期时的观察值指标水平趋势图
点击用户界面右上角,退出用户界面,系统返回数值结果如下:
数据拟合广义帕雷托分布模型,采用间隔最大积估计。位置参数U=1021.9185,尺度参数A=2573.7863,形状参数G=0.2788。拟合结果柯尔莫哥洛夫统计检验KS=0.148370,显著性概率p=0.4786。重现期100年一遇的指标为7696.35。
广义Logistic分布和广义正态分布
广义Logistic 分布和广义正态分布,近年在水文频率分析中应用亦较为广泛。他们和广义极值分布一样含有位置、尺度和形状3个参数。
广义Logistic分布,和广义极值分布一样,近年在水文频率分析中应用亦较为广泛。改分布和广义极值分布一样含有位置、尺度和形状3个参数。广义Logistic分布的概率密度函数形式为:
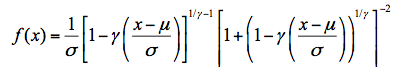
式中, μ为位置参数,σ为尺度参数,是和形状有关的参数。广义Logistic分布累积分布函数为:
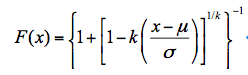
广义Logistic分布,有其名称即可想到,他和广义的极值分布与广义的帕雷托分布有一些相似。
广义正态分布,和广义Logistic分布一样,含有位置、尺度和形状3个参数。广义正态分布的概率密度函数形式为:
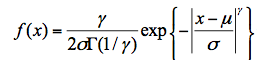
式中, μ为位置参数,σ为尺度参数,是和形状有关的参数。广义正态分布累积分布函数为:
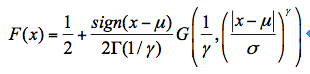
这里,σ>0,>0。为不完全伽玛函数。下面这些分布是广义正态分布的一些特例:当 <0时,具有限下限与正偏斜度,这时即为三参数对数正态分布;当 = 0时为正态分布; 当 >0时,具有有限的上限和负偏斜度,这时为逆对数正态分布。如果<0且μ + σ/ = 0,这时即为两参数的对数正态分布。
DPS应用示例
这两种分布,表达的数据类型极为相似。这里我们以广义Logistic分布数据拟合为例,介绍在DPS系统下的数据处理。这里仍以图42-10所示数据进行广义Logistic分布拟合。分析时,在菜单方式下调用“专业统计”“水文气象频率分析”中的“广义Logistic分布”,这时系统弹出如图42-14所示用户界面。
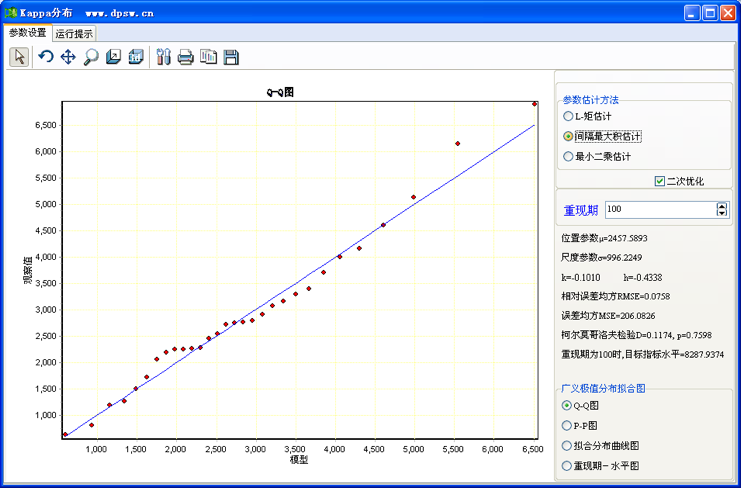
图42-14 广义Logistic分布拟合Q-Q图及其用户界面
和广义极值分析用户界面类似,广义Logistic分布分析用户界面亦显示了估计模型统计结果的拟合程度指标,如柯尔莫哥洛夫统计检验p值、相对均方误差、误差均方,以及图示样本点和理论曲线吻合度(吻合趋势)。
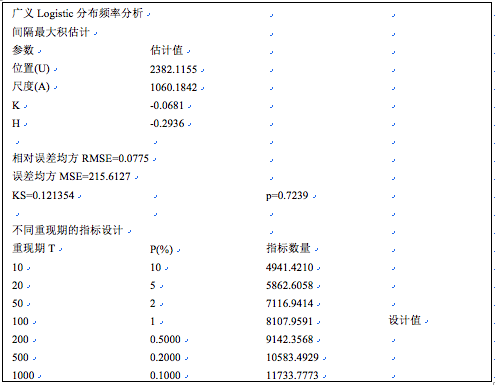
拟合模型是否可以应用, 理论上需要柯尔莫哥洛夫统计检验p值大于0.05。即理论分布和样本实际分布没有显著差异。当然,相对均方误差、误差均方越小越好,图示样本点和理论曲线吻合趋势尽量满意。这里的几种拟合方法,以“间隔最大积估计”拟合结果较好。广义Logistic分布拟合结果和帕雷托分布拟合相比,无论是相对误差均方、还是图形显示,精度显著提高。点击用户界面右上角,退回到编辑状态,得到数值结果如下:
Kappa分布
这里介绍的Kappa分布是一簇呈正偏态、含有4个参数的广义Kappa分布,它首先是由Mielke(1973)、Mielke和Johnson(1973)介绍的。Kappa分布在分析降水、风速、河流流量数据方面受到了较多的关注。如Kappa分布用于检测极端降水事件和降雨序列的频率分析。
Kappa分布的概率密度函数形式为:
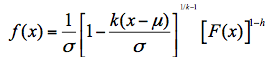
式中, μ为位置参数,σ为尺度参数,k,h是和形状有关的参数。分布函数中,x取值上界:当k>0时,上限为;当k≤0时为无穷大。x取值下界:当h>0时,下界为;当h≤0且k<0时上界为;当h≤0且k≥0时下界为负无穷大。Kappa分布累积分布函数为:

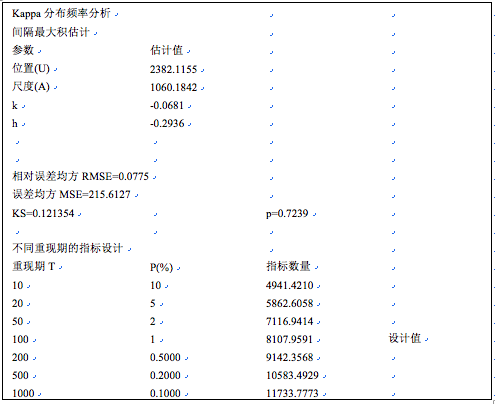
pa分布DPS拟合
Kappa分布DPS的数据处理,仍以图42-10所示数据进行Kappa分布拟合。分析时,在菜单方式下调用“专业统计”“水文气象频率分析”中的“Kappa分布”,这时系统弹出如图42-15所示用户界面。
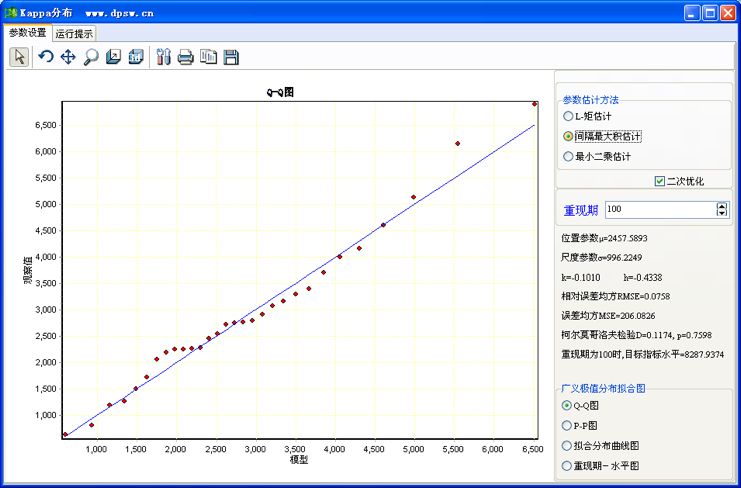
图42-15 Kappa分布拟合Q-Q图及其用户界面
和广义极值分析用户界面类似,Kappa分布分析用户界面亦显示了估计模型统计结果的拟合程度指标,如柯尔莫哥洛夫统计检验p值、相对均方误差、误差均方,以及图示样本点和理论曲线吻合度(吻合趋势)。
拟合模型是否可以应用, 理论上需要柯尔莫哥洛夫统计检验p值大于0.05。即理论分布和样本实际分布没有显著差异。当然,相对均方误差、误差均方越小越好,图示样本点和理论曲线吻合趋势尽量满意。这里的几种拟合方法,以“间隔最大积估计”拟合结果较好。Kappa分布拟合结果和帕雷托分布拟合相比,无论是相对误差均方、还是图形显示,精度显著提高。点击用户界面右上角,退回到编辑状态,得到数值结果如下:
Wakeby分布
韦克比(Wakeby)分布是由H.A.Thomas于1976年定义的。因那年夏天他在马萨诸塞州的避暑别墅眺望一个名为Wakeby的池塘时构思了这一分布,故将其命名为Wakeby分布。Hosking认为Wakeby分布在水文学领域的成功应用与推广是得益于该分布具有下述一些属性:(i) 通过选择合适的参数值,就可以模仿极值分布、对数正态分布、对数伽玛分布。(ii) 该分布具有五个参数,比常见的统计分布系数多,这允许有形式更多的各种形状。前面介绍的广义帕雷托分布仅是Wakeby分布的一个特例。(iii) 该分布具有有限的下限,即物理上合理的许多水文观测指标。(iv) 某些韦克比分布有拖尾的上部尾巴和可以适合偶尔高的“离群值”,这是经常在水文学中观察到的现象。(v) 分布形式是适合于模拟研究。
Wakeby分布函数有些复杂,其解析方程的定义只能以逆函数形式出现,因此Wakeby分布无法获得概率密度函数及其分布函数的显式表达式。逆函数形式为:
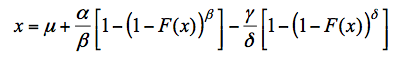
这里F(x)=P(X≤x)。虽然变量x的矩可以作为函数的参数获得,但逆关系却不容易推导出来。因此参数的矩估计不可行。此外,参数的最大似然估计也是不容易获得。因此目前一般用L-矩估计方法来估计分布模型的参数。
Wakeby分布模型拟合数据,待估计参数较多,。5个参数里面除一个位置参数外,尺度参数和形状参数各有两个,这就导致参数间关系不是简单的线性关系。同时,如前所述,Wakeby分布参数有较多条件的限制。些限制使得参数取值空间分布在许多非连续的实数空间里。因此采用目前的拟合方法,参数估计值难以达到最优解。
我们在研究Wakeby分布参数特征基础上,因此在前面几种拟合方法基础上,以前面几种参数估计结果为初始值,再采用随机优化策略,在非连续参数取值空间,寻优优化。即基于随机优化的“二次优化”算法,以使得拟合过程更稳健、精度更高。我们以Castillo(1988)专著中提供的所有14组例子数据,以模型拟合相对残差均方(RMSE)作为拟合精度指标,并定义相对残差均方的下降百分率为二次优化效率(%),公式为:

所有14组例子数据结果见表42-1。
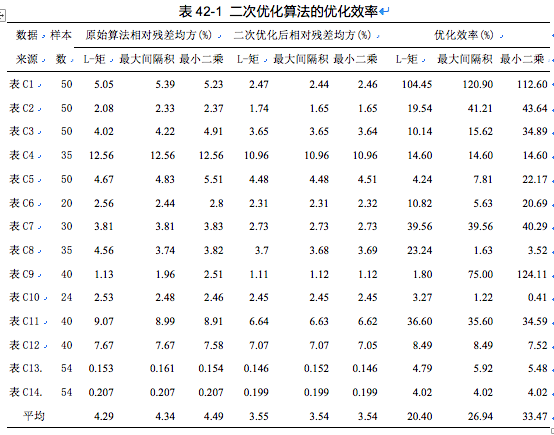
从表42-1可以看出,优化后所有的例子数据以及L-矩估计、 最大间隔积估计和最小二乘估计算法的相对残差均方均有所下降。14组例子数据平均,L-矩法、 最大间隔积法和最小二乘法在优化后的相对残差均方分别下降了20.40%,26.94%和33.47%。 由此可见, 作者提供的二次优化算法可较大幅度提高拟合精度。
Wakeby分布DPS拟合
Wakeby分布DPS的数据处理,仍以图42-8所示数据进行Wakeby分布拟合。分析时,在菜单方式下调用“专业统计”“水文气象频率分析”中的“Wakeby分布”,这时系统弹出如图42-16所示用户界面。
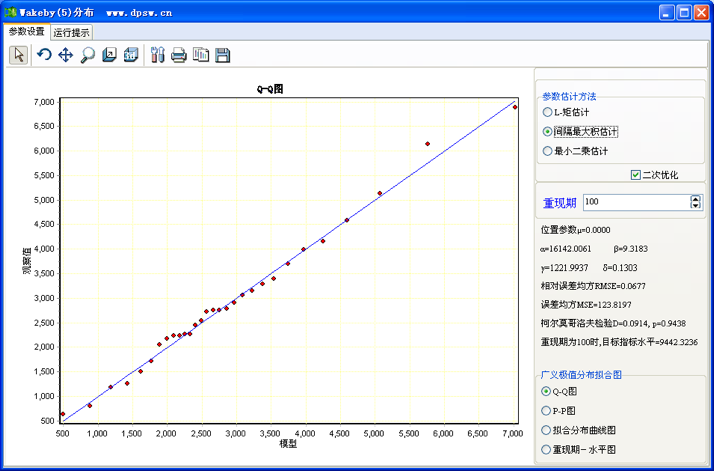
图42-16 Wakeby分布拟合Q-Q图及其用户界面
和广义极值分析用户界面类似,Wakeby分布分析用户界面亦显示了估计模型统计结果的拟合程度指标,如柯尔莫哥洛夫统计检验p值、相对均方误差、误差均方,以及图示样本点和理论曲线吻合度(吻合趋势)。
拟合模型是否可以应用, 理论上需要柯尔莫哥洛夫统计检验p值大于0.05。即理论分布和样本实际分布没有显著差异。当然,相对残差均方、残差均方越小越好,图示样本点和理论曲线吻合趋势尽量满意。这里的几种拟合方法,以“间隔最大积估计”拟合结果最好。Wakeby分布拟合结果和帕雷托分布拟合相比,无论是相对残差均方、还是图形显示,精度都有显著提高。点击用户界面右上角,退回到编辑状态,得到数值结果如下:
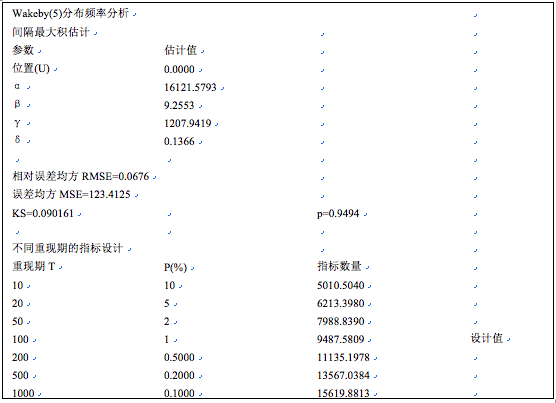
如果采用经典方法进行估计,得到结果为:位置(U)=-107.1049,α=21121.9851,β=11.2127,γ=1169.7228,δ=0.0823。相对误差均方RMSE=9.16(%),误差均方MSE= 218.4749。拟合结果显著不如二次优化结果。
几个主要分布频率分析结果比较
应用于水文频率分析的统计分布类型较多,各个分布拟合精度如何是用户所关心的。我们这里将4个主要分布,即Pearson III型分布(P3)、广义极值分布(GEV)、广义帕雷托分布(GPD)和Wakeby分布(Wak),以及Wakeby分布参数估计二次优化(Wak')应用于Castillo(1988)专著中提供的所有14组例子数据的拟合情况进行比较。比较指标是相对残差均方根(RMSE):
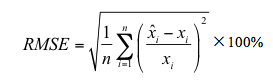
统计分布拟合样本观察值的相对残差均方根结果见表42-2。注意表中列出的是每个频率分布模型采用几种参数估计方法进行估计,取其中RMSE的最小值。
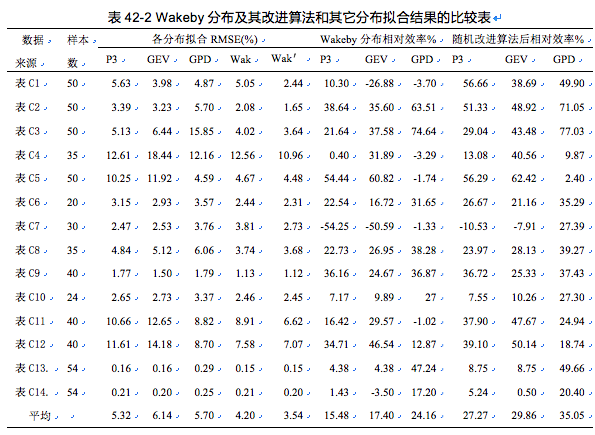
从14组例子数据拟合结果的平均值来看,算法改进后的Wakeby分布参数二次优化(Wak')结果的RMSE值最小,其余从小到大其次是Wakeby分布、Pearson III型分布、广义帕雷托分布和广义极值分布。亦可看出目前我国广为采用的Pearson III型分布,在3参数的频率分布拟合中拟合精度是最高的。传统的Wakeby分布拟合虽然比3参数分布拟合结果要好,但仍有改进算法的必要。
Wakeby分布因参数较多,拟合效果比一般的3参数的统计分布效果要好,从上述表42-2也可看得出来,即平均来说,指标RMSE,较P3、GEV和GPD分别下降了15.48%、17.40%和24.17%。其下降幅度还是较明显的。但是如果采用DPS提供的二次优化算法,RMSE的下降幅度更大,分别达到了27.278%、29.860%和35.05%,差不多下降了30%。因此从拟合精度来考虑,采用随机优化策略,在非连续参数取值空间,寻优优化,使得Wakeby分布参数估计有了新的突破。
主要参考文献
- Castillo E. 1988. Extreme value theory in engineering[M]. New York :Academic Press, Inc.
- Cheng R. C. H.,and N. A. K. Amin. 1983. Estimating parameters in continuous univariate distributions with a shifted origin[J].Journal of the Royal Statistical Society,Ser B, 45(3) :394-403.
- Coles S. 2001. An introduction to statistical modeling of extreme values[M]]. New York:Springer Verlag.
- Hosking, J. R. M. 1990. L-moments: analysis and estimation of distributions using linear combinations of order statistics[J]. Journal of the Royal Statistical Society, Series B,52(1) : 105-124.
- Hosking, J. R. M., and Wallis, J. R. 1997. Regional frequency analysis: an approach based on L-moments[M]. Cambridge University Press, Cambridge
- Ramachandra R. A. and Khaled H . H., 2000. Flood Frequency Analysis[M]. Cambridge University Press, Cambridge
Passing-Bablock回归
发布日期:2016-06-25Passing-Bablok (1983)提出的这一非参数回归分析方法,它特别适合用于两种方法的检测结果无差异的比较分析。Passing-Bablok回归和Theil回归类似,不需特别的数据分布假定,因此亦是一种非参数回归分析方法。另外,与第6章介绍的Deming 回归相似,Passing-Bablok回归在两个变量都含有误差(即不是精确的测量值)时较适用。Passing-Bablok回归可用于恒定或成比例的误差情况, 唯一的限制是假设方差的比例等于斜率的平方。
例 这里仍以第6章Deming回归分析图6-19两种方法测定某物质浓度的例子数据。分析时将数据编辑如图6-19左边。然后进入菜单,选择“试验统计”—“非参数统计”下面的“Passing-Bablock回归”功能项,鼠标点击后系统显示如图9-11所示的用户操作界面。
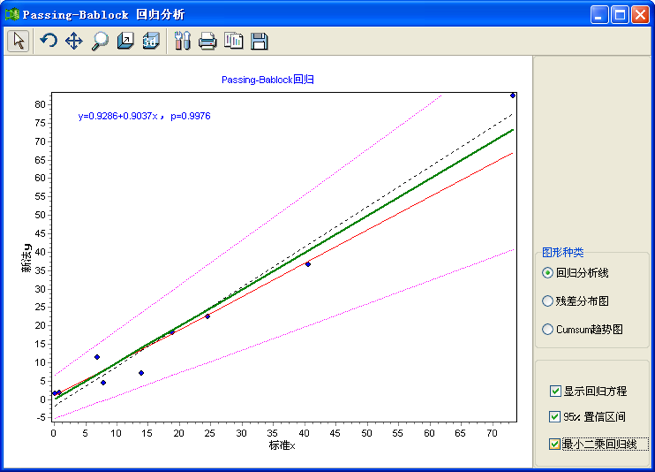
图9-11 Passing-Bablock回归分析用户界面
在这里的用户界面中有3种图形显示:
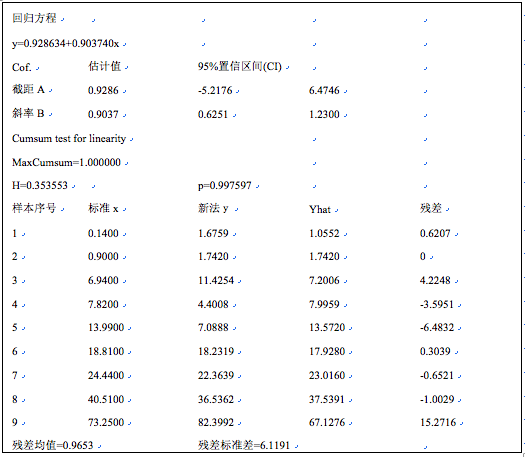
第一个如图9-11所示的回归分析线图。图中绿色粗实线为一致性标识线(identity line),即y=x;红色实线为回归线;粉红色点线(虚线)为回归线的95%置信限;黑色折线为普通最小二乘回归线;蓝色点为原始数据分布。另外在图的左上方可显示当前的Passing-Bablock回归方程,y=0.9286+0.9037x。并显示总体评价模型有效性的线性概率p,p=9976。
第二个是残差分布图。Passing等 (1983)指出,如果统计检验b=1和a=0同时满足,即可推断出y=x,或者换句话说,这两种测验方法是等价的的。但有人认为这是错误的。理由是如果残差的置信区间较大时,两个实验室方法不可比较。因此,使用Passing-Bablok 回归分析进行比较研究不应局限于截距、斜率的估计、以及他们95 %置信区间的计算。代表随机差异的残差也应列入统计分析和方法比较之中。
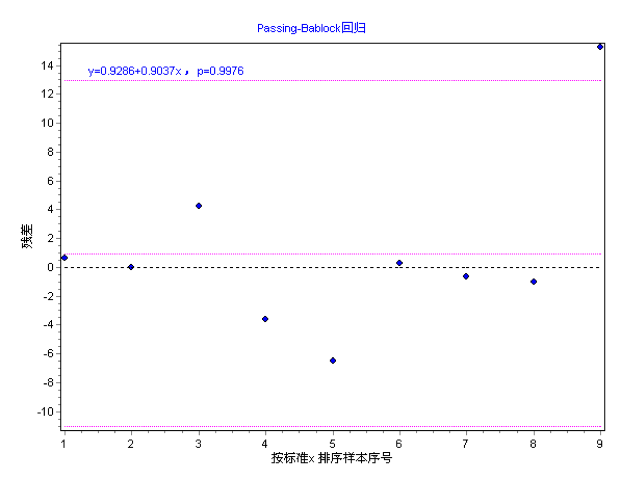
图9-12 Passing-Bablock回归分析残差分布图
残差分布图显示的残差标准偏差 (RSD) 是两种方法之间的随机差异测度。95%的随机差异预计位于间隔-1.96 RSD到+1.96 RSD。如果此间隔较大,表明这两种方法测量结果可能不相同。
第三个是线性累积和检验,以总体上评价线性模型的有效性。给出的统计检验显著水平p值,只有当p值大于0.05时,方可认为线性较好,无明显偏差。图19-13为线性适合度检测的Cumsum值曲线。
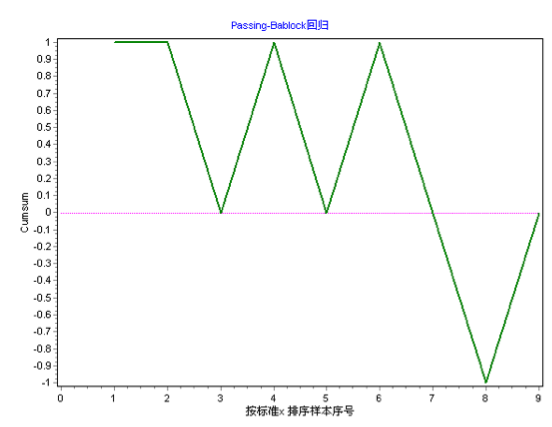
图9-13 Passing-Bablock回归Cumsum线性检验趋势图
从图形用户界面初步了解分析结果之后,退出用户界面,这时系统返回统计分析数值结果如下:
一般线性模型方差分析的均值比较图和残差诊断图
发布日期:2016-03-18线性模型处理效应一般可用均值-误差直方图(图5-3)表示。误差定义有标准差、标准误等形式,DPS这里的误差定义为标准差。且在直方图上只标注正的误差(标准差)。

图5-3 处理效应直方图
残差诊断
方差分析的条件有一个提法是正态分布假定。因此不少科研工作者认为试验处理结果数据须呈正态分布方可进行方差分析,并寻求对每个处理进行正态性检验以验证满足方差分析的条件,其实这是一种误解。例如随机区组设计试验情形下,如果每一个处理、每一个区组都存在差异,那么每个处理单元的观察值大小由于受区组、处理的影响、其分布趋势可能不再是随机的正态分布,即试验结果数据不会符合我们所要求的正态分布假定。
方差分析中所谓正态分布假定实际上是从试验观察结果中提取出了各种处理效应之后的残差应该呈现为正态分布。在应用线性模型进行方差分析时,线性模型的残差项应满足独立性、等方差性和正态性的假设。例如,对于来自一个总体的一组数据,我们欲检验他们是否符合正态分布,可以从线性模型的观点理解为一个仅含有均值(μ)效应的线性模型:
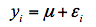
移项后有εi = yi - μ,即从观察值yi去掉(或提取出)均值μ之后的残差εi是否满足独立性、等方差性和正态性的假设。对于完全随机设计方差分析,其线性模型除含有均值μ之外,还有一个处理效应(αi),模型形式为:
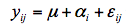
这时的独立性、等方差性和正态性的假设应是试验观察结果yij去掉总的均值μ及处理效应αi之后的残εij是否是否满足这些假设。而随机区组设计试验方差分析的线性模型则更复杂点:
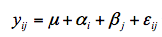
其正态分布假定应该是观察值yij去掉总的均值μ、处理效应αi、区组效应βj之后的残差εij是否满足独立性、等方差性和正态性的假设。
上面几个线性模型表达式中,理论上残差项应该满足独立性、等方差性和正态性的假设,这也是方差分布所要求的正态分布假定。
DPS对残差的正态性检验,提供了如下用户图形界面(图5-4)。
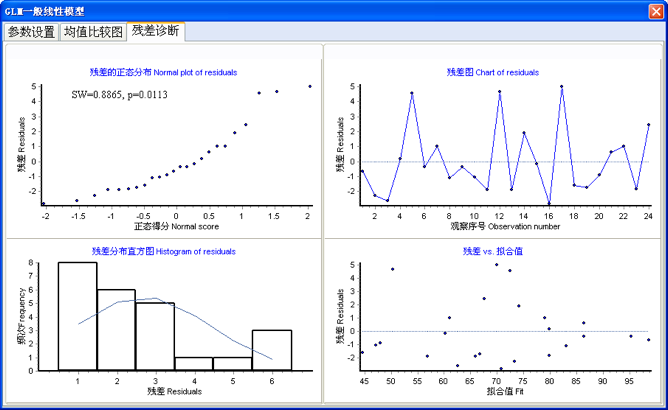
图5-4 残差正态分布检验图示
DPS中,线性模型残差项正态分布辨识,其直观的有Q-Q图和直方图。Q-Q图以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为直角坐标系的散点。如果资料服从正态分布,则样本点应该呈一条直线。直方图是按残差在某一区间出现次数频率,判断出现频率是否是钟形分布。
图5-4的右侧为残差随试验点序号和线性模型拟合值大小的曲线(散点图),可以看出残差点的分布是否随机(或有某种趋势)。如果残差数据点表现平稳、随机分布,即可认为满足线性模型的各种假设条件。但如果残差点表现出某种趋势,这时就要注意,模型残差可能具有某种异质性、或尚有某些效应有待提取。
除图示方法外,DPS还采用Shapiro- Wilk检验法对残差分布正态性进行检验。Shapiro—Wilk检验法是S. S. Shapiro与M. B. Wilk提出用顺序统计量W来检验分布的正态性。对研究对象总体,该方法先提出假设认为总体服从正态分布,再将样本量为n的样本按大小顺序排列编秩。根据样本量为n时所对应的系数αi,由特定公式计算出检验统计量W,并根据统计量W计算显著性概率p值。检验结果,如果p值大于0.05,可接受残差服从正态分布。
除图示方法外,DPS还采用Shapiro- Wilk检验法对残差分布正态性进行检验。Shapiro—Wilk检验法是S. S. Shapiro与M. B. Wilk提出用顺序统计量W来检验分布的正态性。对研究对象总体,该方法先提出假设认为总体服从正态分布,再将样本量为n的样本按大小顺序排列编秩。根据样本量为n时所对应的系数αi,由特定公式计算出检验统计量W,并根据统计量W计算显著性概率p值。检验结果,如果p值大于0.05,可接受残差服从正态分布。
增广NCII设计
发布日期:2016-02-25增广NCII设计,是指在NCII设计含f×m个杂交组合基础上、再添加f+m个纯系亲本的遗传交配设计。该设计可对被研究性状的合适遗传模型(即加性,加悭显性,或加性一显性一上位性)作出统计选择;同时,还能对雌、雄亲的有关基因频率的同质性进行统计测验(莫惠栋、李志明,1991)。增广NCII设计采用Hayman的Vr-Wr分析法对增广设计的fm+f+m个家系的试验数据进行遗传模型的统计检验。
增广NCII设计试验结果统计分析的数据格式如下图41-20:

图41-20 增广NCII试验数据编辑格式
选中数据后,执行“专业统计”中的“遗传交配设计统计”下面的“增广NCII设计”功能后,系统给出要求用户输入父本数、母本数的用户界面。
在用户界面输入正确的参数后,系统立即给出如下计算结果:
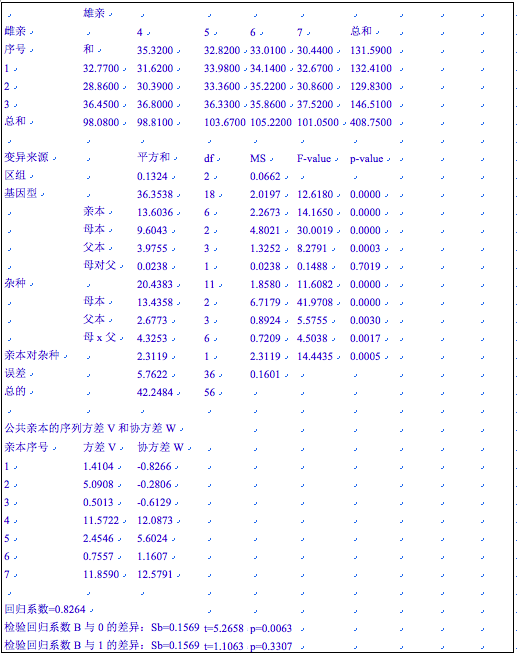
协方差分析中,对回归系数进行统计测验,H0: F+M =0,t=5.2658,p=0.0063;极显著;测验H0: F+M =1,t=1.1063,p=0.3307,不显著.故又可进而测验H0:pq=uv,得F=31.632,p=0.029,显著。这表明性状的遗传符合加性-显性模型,但控制该性状的增、减效等位基因频率在雌、雄亲间不相等。
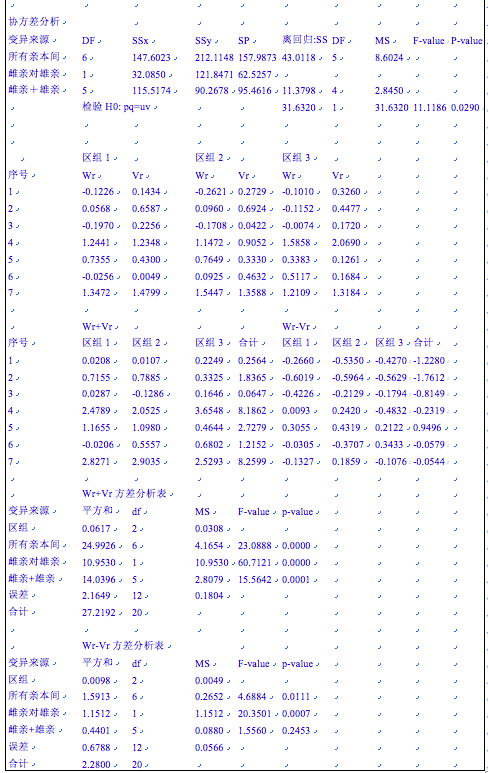
由公共亲本系列的Wr对Vr值计算得到的Wr+Vr和Wr-Vr,进行方差分析。结果显示,检验H0:h=0,为极显著(F=15.56,p<0.0001);检验H0:I=0,为不显著(F=1.156, p=0.2453) 测验H0:pq=uv,为极显著(F=60.71和20.35, p值均小于0.01)。因此结论与协方差分析完全相同(一般地说,若协方差分析已获明确结论,就不必再作方差分析)。
格子设计统计分析
发布日期:2016-01-05当试验处理数量很大时,Yate(1936)提出了一种不完全区组设计,即格子设计(Lattice design)方法。格子设计克服了重复内分组设计中组间处理比较和组内处理比较精确度悬殊的问题,并对处理分组方法采取将固定分组改为不固定分组。这样使一个处理有机会和许多其他处理,甚至其他各个处理都在同一区组中相遇过。
4.7.1 格子设计类别
格子设计,一类是以平方格子及其扩展而来的平方格子设计、矩形格子设计和立方格子设计。这类设计的处理数受限于必须等于每个区组内处理数k的平方,3次方,k(k+1)等的限制。因此处理数的设置不是很灵活。另一类是称之-设计的广义格子设计,它对于可用区组容量整除的任何处理数、2-4次重复、均可构成不完全区组设计。且构成方法简便,设计效率高。
1.平方格子设计
当处理数为区组内处理个数的平方时,称为平方格子设计(squared lattice,区组内处理个数为k,全部处理个数为k2)。平方格子设计一般用于处理数量大时的比较试验。按照同一重复内各区组在田间排列的方法可以分为:仿照随机区组式的(整个重复不必成方形)和仿照拉丁式的(整个重复内各区组联成方形)。这两者又各因每一品种是否在不同区组中都相遇过而分为平衡与部分平衡两种情况。平衡格子设计在对品种间比较时的精确性是一致的,但重复数可能较大,在应用中有所限制;部分平衡设计。
2.矩形格子设计
当区组内处理数为k个,而区组数为(k+1)个,共k(k+1)个处理,这时生成的格子设计为矩形格子设计。它适合为处理数是12、20、30、42、56、72、90和110时的比较试验处理。矩形设计将全部处理安排于区组个数为k个小区的的k+1个不完全区组中,即构成一个重复。
3.立方格子设计
立方格子设计可容纳大数量处理的试验设计。其供试处理个数为区组数k的立方,即k3。它适合为处理数是64、125、216、343、512、729,乃至处理数为1000时的比较试验处理。但区组个数仍为k(每个重复有k2个区组),因此仍能对环境进行严格控制。
4.α-格子设计
α-设计由Patterson和Williams等提出,亦称为广义格子设计(Generalized lattice design)。格子设计增加了一个虚拟因子参数s,只要处理数t等于每个区组内处理数k的s整数倍,即t=ks,便可给出相应的格子设计。这种特性使得格子设计不再受限于k的大小影响,而使得处理数t的设置更为灵活。
4.7.2 格子设计试验数据统计分析
格子设计试验结果的统计分析,经典方法是基于Yates提出的恢复区组间信息分析的方差分析法。这类方法视区组效应为随机,利用了不完全区组间方差的附加信息,其原理基于多因子试验的分析,采用手工计算,步骤繁复,且只适用于平方格子设计、矩形格子设计和立方格子设计。方差分析过程中离差平方和的分解因试验设计不同而不同。没有一个通用的分解模式,故实际应用起来较为困难。
DPS数据处理系统对各种格子设计试验数据的统计分析,采用的是根据Patternson和Thompson(1971)提出的限制最大似然估计(Restricted maximum likelihood, REML)方法实现的计算机迭代算法。该方法可把数据分解为不相关的两个部分:一部分用于估计方差分量、另一部分用于估计处理效应。应用这种方法可对多种格子试验设计方案进行分析,如平方格子设计、部分平衡格子方设计、矩形格子设计、-格子设计等试验均可进行统计分析。
4.7.3 DPS平台的操作示例
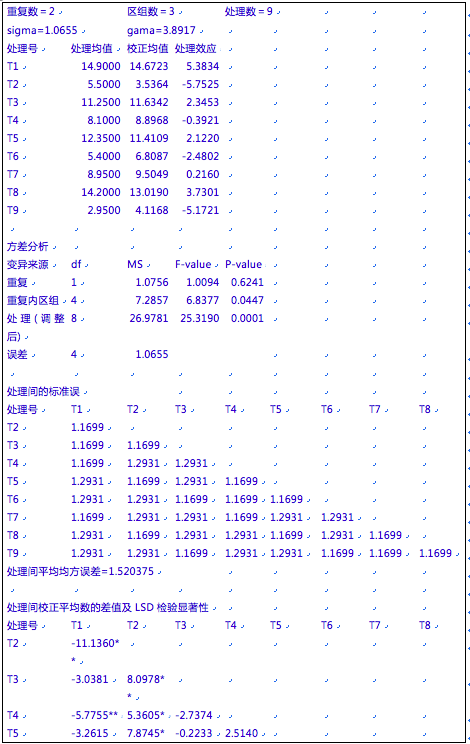
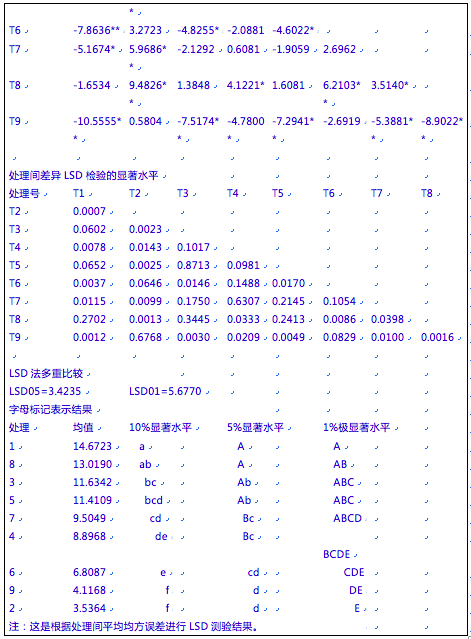
在DPS电子工作表中将试验数据按重复、区组、处理和观察值,共4列数据,一个处理(观察值)占一行的方式输入(图40-12)。重复、区组和处理须按自然数、从1开始的顺序依次编号。
图40-12格子设计统计分析数据格式
然后选中重复、区组、处理和观察值这4列数据(如图40-12阴影部分),进入主菜单,选择“专业统计”下面的“品种区试及其他农学试验统计”里面的“格子设计统计分析”功能项,执行格子设计试验数据的统计分析功能后,系统返回分析结果到DPS电子工作表里面。
输出主要结果包括三个部分:①各个处理均值及调整(校正)后的均值;②各个变异来源的方差分析表;③各个处理的调整值之间的标准误、差值(其后标有星号的表示最小显著性差异(LSD)检验的差异显著性)、及其差值LSD显著性检验显著性水平p值等多重比较结果。该例数据经DPS统计分析,输出结果如下: